Method
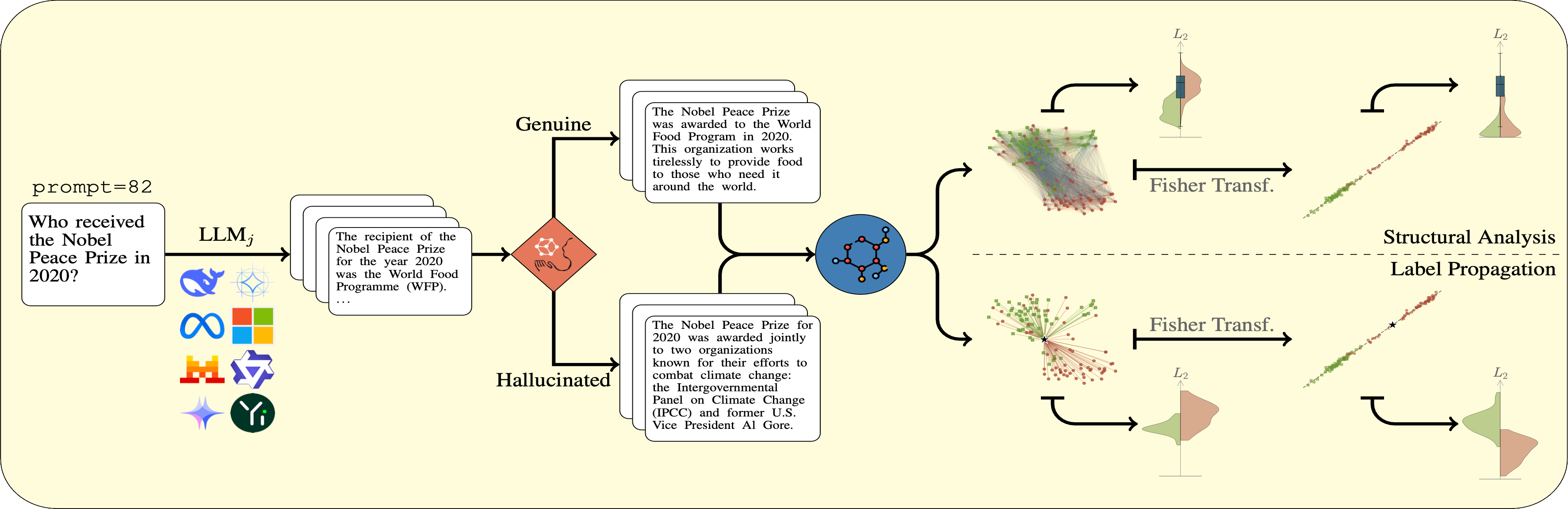
Structural Analysis
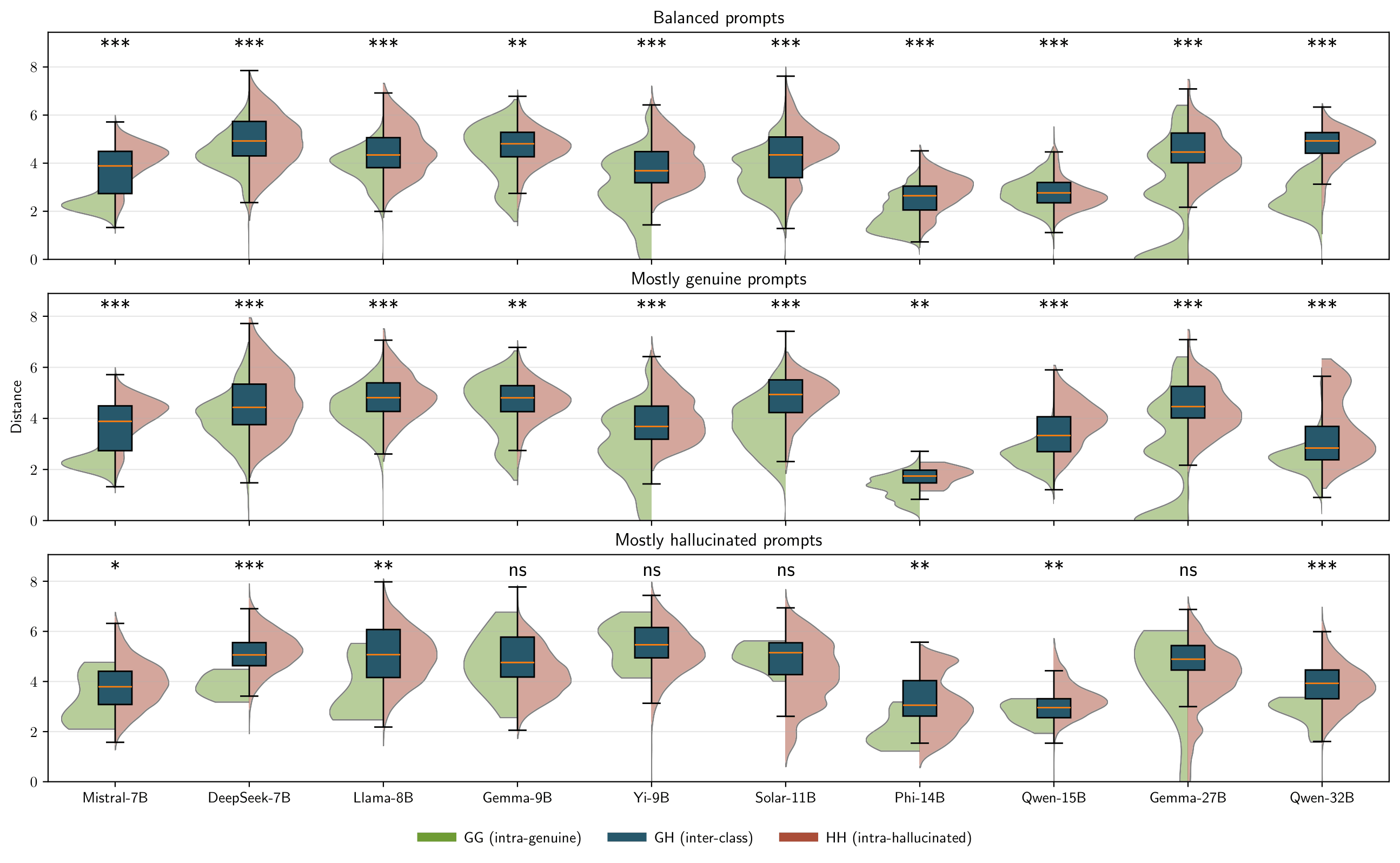
Under APORIA we test a simple hypothesis: for a given prompt, genuine responses concentrate around a stable semantic core, while hallucinated ones scatter into distinct fabricated explanations.
- Distance distributions. For each pair of embedded responses we collect the pairwise Euclidean distance, yielding three distributions: intra-genuine DGG, intra-hallucinated DHH, and inter-class DGH.
- Wasserstein comparison. Rather than reducing the distributions to low-order moments, we compare them via the one-dimensional Wasserstein distance, measuring the separation between DGG and DHH.
Label Propagation
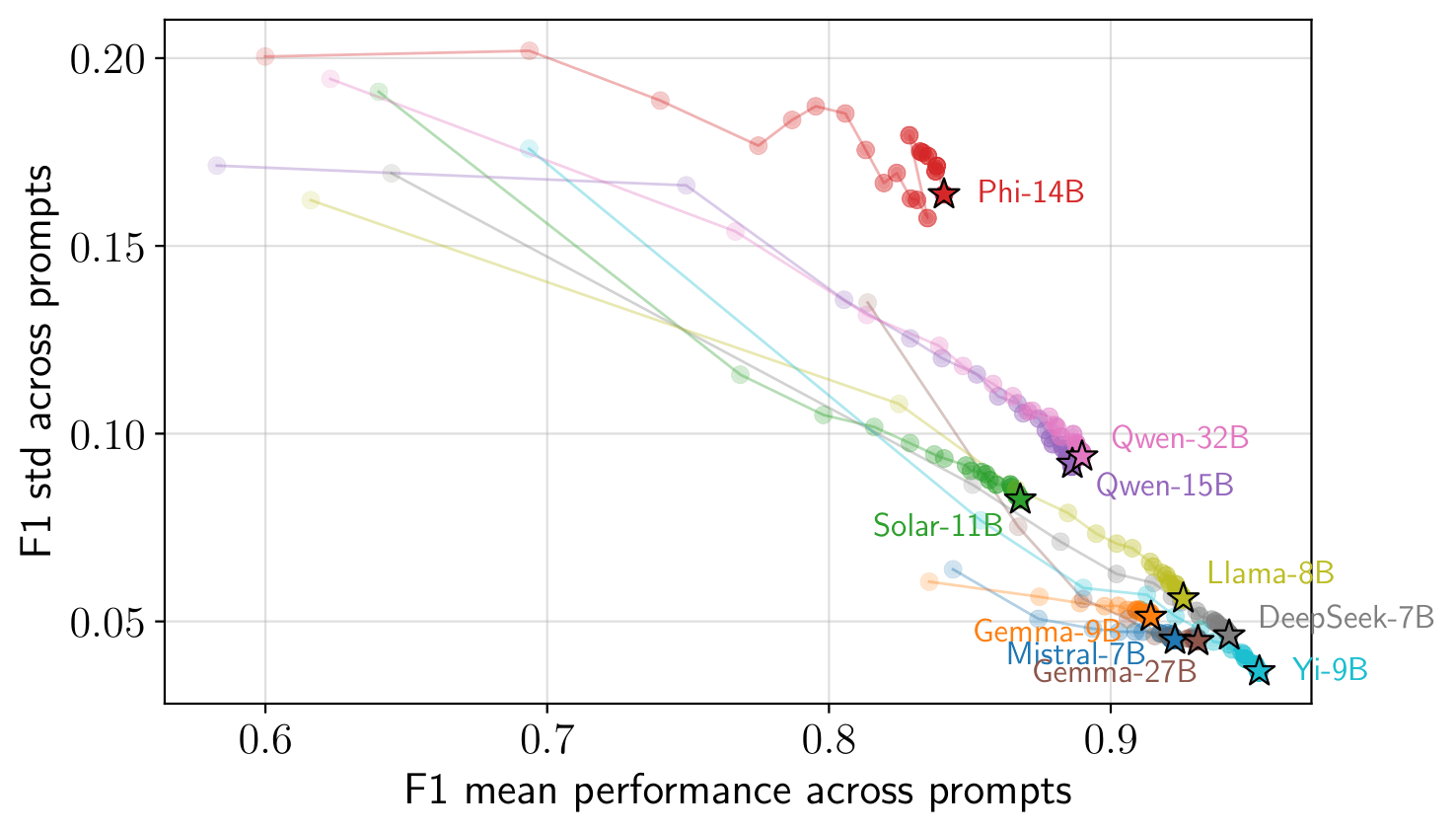
Building on this geometric structure, APORIA-LP is a supervised procedure that propagates labels from a small annotated subset to the remaining responses.
- Point-to-set distances. For an unlabelled response we compute its distances to each labelled class, producing two empirical distributions.
- Label assignment. The response is assigned to the class — G or H — whose internal distance structure is most consistent with these distributions.